Jump to content
DevOps Forum
Sign In
Home
visualization
DevOps Forum
Featured Content
All Activity
Forums
Events
Online Users
Leaderboard
Members List
Search
Contact Us
More
More
Featured Content
All Activity
Forums
Events
Online Users
Leaderboard
Members List
Search
Contact Us
Existing user? Sign In
Sign In
Email Address
Password
Remember me
Not recommended on shared computers
Sign In
Forgot your password?
Or sign in with...
Sign in with LinkedIn
Sign in with X
Sign in with Google
Sign in with Facebook
Sign Up
Home
visualization
Search...
#
visualization
Followers
Sort By
Recently Updated
Title
Start Date
Most Commented
Most Viewed
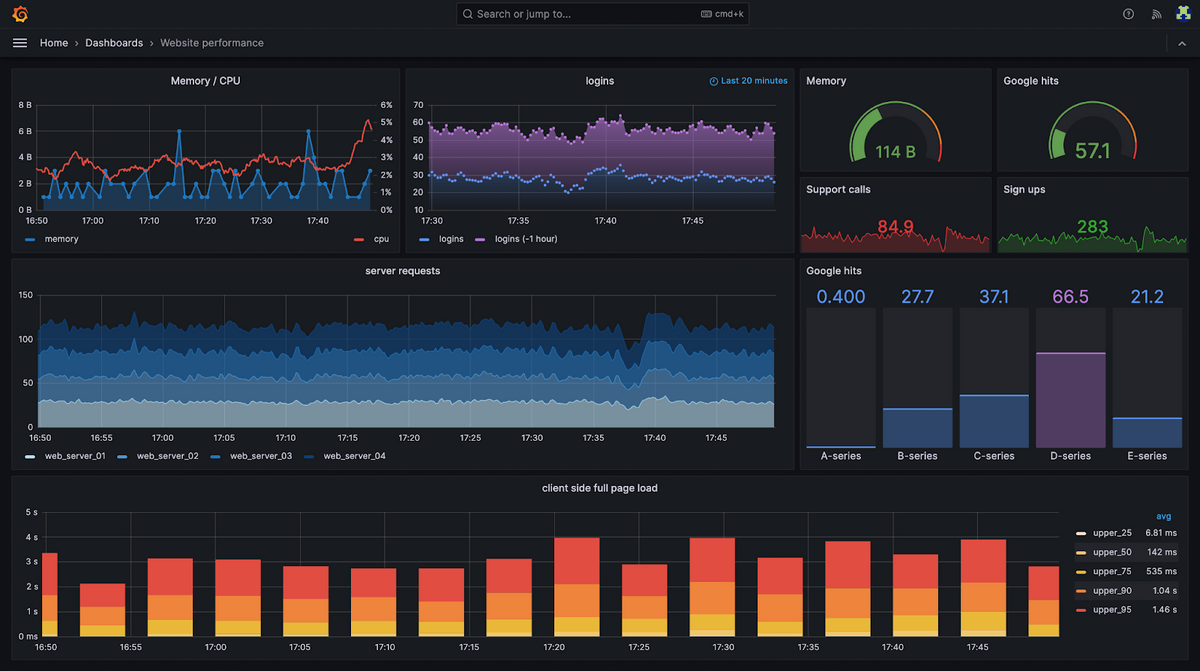
How Grafana Works
How Grafana Works
KodeKloud
·
April 23, 2024
1 yr
grafana
dashboards
explainers
grafana labs
+2 more
Tagged with:
dashboards
explainers
grafana labs
open source
visualization
2 comments
475 views
James
April 27, 2024
1 yr
Amazon Elasticsearch Service adds Gantt charts for visualizing events, steps and tasks
Amazon Elasticsearch Service adds Gantt charts for visualizing events, steps and tasks
Amazon Web Services
·
November 24, 2020
4 yr
aws
elasticsearch
gantt
visualization
2 comments
512 views
Guest
March 4, 2022
3 yr
Home
visualization
All Activity
Refresh
Sign In
Sign Up
Search
Menu
Close panel
Account
Close panel
Existing user? Sign In
Sign Up
Close panel
Navigation
Close panel
Featured Content
All Activity
Forums
Events
Online Users
Leaderboard
Members List
Search
Contact Us
Home
visualization
Close panel
Search
Close panel
Search
Where:
Everywhere
Topics
Events
Members
Search:
Content titles and body
Content titles only
Date Created:
Any date
Past 24 hours
Past week
Past month
Past six months
Past year
Use:
All of these words
Any of these words
Last Updated:
Any date
Past 24 hours
Past week
Past month
Past six months
Past year
Search
Everywhere
Topics
Events
Members
Find results in
Search titles and body
Search titles only
Date Created
Created any time
Created past 24 hours
Created past week
Created past month
Created past 6 months
Created past year
Last Updated
Updated any time
Updated past 24 hours
Updated past week
Updated past month
Updated past 6 months
Updated past year
.png.6dd3056f38e93712a18d153891e8e0fc.png.1dbd1e5f05de09e66333e631e3342b83.png.933f4dc78ef5a5d2971934bd41ead8a1.png)
.thumb.jpg.10b3e13237872a9a7639ecfbc2152517.jpg)
