.png.6dd3056f38e93712a18d153891e8e0fc.png.1dbd1e5f05de09e66333e631e3342b83.png.933f4dc78ef5a5d2971934bd41ead8a1.png)
Search the Community
Showing results for tags 'video'.
Found 16 results
-
 OpenAI's new Sora text-to-video generation tool won't be publicly available until later this year, but in the meantime it's serving up some tantalizing glimpses of what it can do – including a mind-bending new video (below) showing what TED Talks might look like in 40 years. To create the FPV drone-style video, TED Talks worked with OpenAI and the filmmaker Paul Trillo, who's been using Sora since February. The result is an impressive, if slightly bewildering, fly-through of futuristic conference talks, weird laboratories and underwater tunnels. The video again shows both the incredible potential of OpenAI Sora and its limitations. The FPV drone-style effect has become a popular one for hard-hitting social media videos, but it traditionally requires advanced drone piloting skills and expensive kit that goes way beyond the new DJI Avata 2. Sora's new video shows that these kind of effects could be opened up to new creators, potentially at a vastly lower cost – although that comes with the caveat that we don't yet know how much OpenAI's new tool itself will cost and who it'll be available to. What will TED look like in 40 years? For #TED2024, we worked with artist @PaulTrillo and @OpenAI to create this exclusive video using Sora, their unreleased text-to-video model. Stay tuned for more groundbreaking AI — coming soon to https://t.co/YLcO5Ju923! pic.twitter.com/lTHhcUm4FiApril 19, 2024 See more But the video (above) also shows that Sora is still quite far short of being a reliable tool for full-blown movies. The people in the shots are on-screen for only a couple of seconds and there's plenty of uncanny valley nightmare fuel in the background. The result is an experience that's exhilarating, while also leaving you feeling strangely off-kilter – like touching down again after a sky dive. Still, I'm definitely keen to see more samples as we hurtle towards Sora's public launch later in 2024. How was the video made? (Image credit: OpenAI / TED Talks) OpenAI and TED Talks didn't go into detail about how this specific video was made, but its creator Paul Trillo recently talked more broadly about his experiences of being one of Sora's alpha tester. Trillo told Business Insider about the kinds of prompts he uses, including "a cocktail of words that I use to make sure that it feels less like a video game and something more filmic". Apparently these include prompts like "35 millimeter", "anamorphic lens", and "depth of field lens vignette", which are needed or else Sora will "kind of default to this very digital-looking output". Right now, every prompt has to go through OpenAI so it can be run through its strict safeguards around issues like copyright. One of Trillo's most interesting observations is that Sora is currently "like a slot machine where you ask for something, and it jumbles ideas together, and it doesn't have a real physics engine to it". This means that it's still a long way way off from being truly consistent with people and object states, something that OpenAI admitted in an earlier blog post. OpenAI said that Sora "currently exhibits numerous limitations as a simulator", including the fact that "it does not accurately model the physics of many basic interactions, like glass shattering". These incoherencies will likely limit Sora to being a short-form video tool for some time, but it's still one I can't wait to try out. You might also like OpenAI just gave artists access to Sora and proved the AI video tool is weirder and more powerful than we thoughtOpenAI's new voice synthesizer can copy your voice from just 15 seconds of audioElon Musk might be right about OpenAI — but that doesn't mean he should win View the full article
OpenAI's new Sora text-to-video generation tool won't be publicly available until later this year, but in the meantime it's serving up some tantalizing glimpses of what it can do – including a mind-bending new video (below) showing what TED Talks might look like in 40 years. To create the FPV drone-style video, TED Talks worked with OpenAI and the filmmaker Paul Trillo, who's been using Sora since February. The result is an impressive, if slightly bewildering, fly-through of futuristic conference talks, weird laboratories and underwater tunnels. The video again shows both the incredible potential of OpenAI Sora and its limitations. The FPV drone-style effect has become a popular one for hard-hitting social media videos, but it traditionally requires advanced drone piloting skills and expensive kit that goes way beyond the new DJI Avata 2. Sora's new video shows that these kind of effects could be opened up to new creators, potentially at a vastly lower cost – although that comes with the caveat that we don't yet know how much OpenAI's new tool itself will cost and who it'll be available to. What will TED look like in 40 years? For #TED2024, we worked with artist @PaulTrillo and @OpenAI to create this exclusive video using Sora, their unreleased text-to-video model. Stay tuned for more groundbreaking AI — coming soon to https://t.co/YLcO5Ju923! pic.twitter.com/lTHhcUm4FiApril 19, 2024 See more But the video (above) also shows that Sora is still quite far short of being a reliable tool for full-blown movies. The people in the shots are on-screen for only a couple of seconds and there's plenty of uncanny valley nightmare fuel in the background. The result is an experience that's exhilarating, while also leaving you feeling strangely off-kilter – like touching down again after a sky dive. Still, I'm definitely keen to see more samples as we hurtle towards Sora's public launch later in 2024. How was the video made? (Image credit: OpenAI / TED Talks) OpenAI and TED Talks didn't go into detail about how this specific video was made, but its creator Paul Trillo recently talked more broadly about his experiences of being one of Sora's alpha tester. Trillo told Business Insider about the kinds of prompts he uses, including "a cocktail of words that I use to make sure that it feels less like a video game and something more filmic". Apparently these include prompts like "35 millimeter", "anamorphic lens", and "depth of field lens vignette", which are needed or else Sora will "kind of default to this very digital-looking output". Right now, every prompt has to go through OpenAI so it can be run through its strict safeguards around issues like copyright. One of Trillo's most interesting observations is that Sora is currently "like a slot machine where you ask for something, and it jumbles ideas together, and it doesn't have a real physics engine to it". This means that it's still a long way way off from being truly consistent with people and object states, something that OpenAI admitted in an earlier blog post. OpenAI said that Sora "currently exhibits numerous limitations as a simulator", including the fact that "it does not accurately model the physics of many basic interactions, like glass shattering". These incoherencies will likely limit Sora to being a short-form video tool for some time, but it's still one I can't wait to try out. You might also like OpenAI just gave artists access to Sora and proved the AI video tool is weirder and more powerful than we thoughtOpenAI's new voice synthesizer can copy your voice from just 15 seconds of audioElon Musk might be right about OpenAI — but that doesn't mean he should win View the full article
-
Something strange is going on with Amazon Prime Video. A report from news site Cord Busters originally claimed that the tech giant quietly pulled the plug on the service in the United Kingdom. If you head over to Amazon Prime’s UK page, you’ll notice that Prime Video isn’t among the list of plans near the bottom. All you see are Prime Monthly and Prime Annuals. The same thing is happening on the American website. Scroll down to the “Choose Your Plan” section and it’s not there. As it turns out, Prime Video continues to exist although it’s being obscured. If you go down to the bottom of the UK website, you’ll find Prime Video listed among the other subscription plans with a direct link to sign up. This isn’t the case with the US page, however. There isn't a clear indicator of Prime Video’s availability in the States; not a cornered-off section or even a small hint. Luckily, the subscription’s signup page is still live if you know where to look or if you have a link. The cost of the subscription hasn’t changed. It’s still $8.99/£5.99 a month. On the Amazon mobile app, it’s featured more prominently. Prime Video is tucked away in the settings menu behind a single expandable tab and it’s still available for download from app stores. All seems good, right? Not exactly, as on mobile, we couldn’t purchase Prime Video by itself. Instead, we were being pushed to buy the regular Amazon Prime plan at $14.99 a month. There was no option for the cheaper service. Amounting problems We don't know what to make of this. On one hand, it may be the start of a new effort to drive up more revenue. By hiding or possibly even ending the service, the platform could be forcing people to purchase the more expensive Amazon Prime if they want to watch shows like Fallout. It's entirely possible. Back in late January 29, Prime Video introduced an ad-supported plan as the new base service which understandably annoyed a lot of people. They had to cough up an extra $2.99/£2.99 a month to get rid of commercials. However, the sudden disappearance of Prime Video could be the cause of recent bugs. Recently, people have begun to notice weird problems with the service. Second episodes for certain shows are coming out before the first, audio for entire languages is missing, and translation errors are just some of the issues viewers have run into. We're leaning towards the glitches as the source of Prime Video's disappearance. Amazon has reportedly disputed Cord Busters' claim in a statement to Engadget saying Prime Video is "still available in the US as a standalone... subscription." Hopefully, this will remain the case. It’s currently one of the cheaper streaming options out there as compared to the other major services. The whole situation could be a bug or bad code wreaking havoc. But something tells us there's more to this story. If you’re looking for something to watch over the weekend, check out TechRadar’s latest roundup of the seven newest movies and shows on Netflix, Prime Video, and Max. You might also like Amazon Memorial Day sales 2024: everything we knowPrime Video movie of the day: M3GAN is Verhoeven-lite satirical horror that I could not have loved morePrime Video’s hit Fallout series is returning for season 2 – looks like we’re going to New Vegas View the full article
-
 Adobe today debuted several new AI features for Premiere Pro, software designed for professional video editing. Adobe's Premiere Pro is set to gain useful editing functions powered by generative AI, which will let video editors do more with less work. With a Generative Extend feature, Premiere Pro will be able to add frames to make video clips longer, allowing for properly timed edits and smooth transitions by extending a scene. Objects in videos will also be able to be added or removed through smart selection and tracking tools. Adobe says that video editors can do things like remove an unwanted item, change an actor's wardrobe, or add set dressings like paintings on the wall or plants on a desk. Perhaps the most interesting new feature is an option to create new video footage directly within Premiere Pro using a text to video feature. Users will be able to type text into a prompt or upload images to create video, and the resulting clips can be used for B-roll, creating storyboards, and more. Adobe plans to introduce these generative AI tools later in 2024. Apple has its own professional video editing software, Final Cut Pro. Final Cut Pro is a Premiere Pro competitor, and as of now, it is lacking in the AI department. Apple has not announced any AI features for Final Cut Pro, but with AI capabilities rumored to be coming to multiple apps in iOS 18 and macOS 15, we could perhaps see some new AI feature additions for Final Cut Pro.Tag: Adobe This article, "Adobe Premiere Pro Gains AI Tools to Add and Remove Objects From Videos, Extend Clips and More" first appeared on MacRumors.com Discuss this article in our forums View the full article
Adobe today debuted several new AI features for Premiere Pro, software designed for professional video editing. Adobe's Premiere Pro is set to gain useful editing functions powered by generative AI, which will let video editors do more with less work. With a Generative Extend feature, Premiere Pro will be able to add frames to make video clips longer, allowing for properly timed edits and smooth transitions by extending a scene. Objects in videos will also be able to be added or removed through smart selection and tracking tools. Adobe says that video editors can do things like remove an unwanted item, change an actor's wardrobe, or add set dressings like paintings on the wall or plants on a desk. Perhaps the most interesting new feature is an option to create new video footage directly within Premiere Pro using a text to video feature. Users will be able to type text into a prompt or upload images to create video, and the resulting clips can be used for B-roll, creating storyboards, and more. Adobe plans to introduce these generative AI tools later in 2024. Apple has its own professional video editing software, Final Cut Pro. Final Cut Pro is a Premiere Pro competitor, and as of now, it is lacking in the AI department. Apple has not announced any AI features for Final Cut Pro, but with AI capabilities rumored to be coming to multiple apps in iOS 18 and macOS 15, we could perhaps see some new AI feature additions for Final Cut Pro.Tag: Adobe This article, "Adobe Premiere Pro Gains AI Tools to Add and Remove Objects From Videos, Extend Clips and More" first appeared on MacRumors.com Discuss this article in our forums View the full article -
 The Western Digital-owned SanDisk continues to push the envelope in SD card storage and speeds. View the full article
The Western Digital-owned SanDisk continues to push the envelope in SD card storage and speeds. View the full article
-
 Today, AWS announces the release of workflow monitor for live video, a media-centric tool to simplify and elevate the monitoring of your video workloads. Accessible via the AWS Elemental MediaLive console and API, workflow monitor discovers and visualizes resources. It creates signal maps showing video across AWS Elemental MediaConnect, MediaLive, and MediaPackage along with Amazon S3 and Amazon CloudFront to provide end-to-end visibility. With the workflow monitor, you can create your own alarm templates or start from a set of recommended alarms, and build custom templates for alarm notifications. View the full article
Today, AWS announces the release of workflow monitor for live video, a media-centric tool to simplify and elevate the monitoring of your video workloads. Accessible via the AWS Elemental MediaLive console and API, workflow monitor discovers and visualizes resources. It creates signal maps showing video across AWS Elemental MediaConnect, MediaLive, and MediaPackage along with Amazon S3 and Amazon CloudFront to provide end-to-end visibility. With the workflow monitor, you can create your own alarm templates or start from a set of recommended alarms, and build custom templates for alarm notifications. View the full article -
One of the most popular uses for Apple's Vision Pro headset is to enjoy movies and TV shows on its enormous virtual screen, but not all streamers are on board. Netflix in particular caused some disappointment when it said it had no plans to make a native Vision Pro app for its service. Not to worry. Independent developer Christian Privitelli has stepped in to deliver what some streamers won't. His app, Supercut, lets you stream Netflix and Prime Video, and is designed specifically for Apple's virtual viewer. The app works much like Apple's own TV Plus app, but instead of Apple content it offers Netflix and Prime Video without the letterboxing you get when viewing shows and movies from the headset's web browser. It's not packed with gimmicks and doesn't have the pleasant virtual theater of the Disney Plus app, but it's cheap and effective, and that's good enough for me. Say hello to Supercut.My Netflix and Prime Video app for Vision Pro is now available to download on the App Store. pic.twitter.com/V9wKLnCSPyApril 6, 2024 See more What Redditors are saying about Supercut for Vision Pro If you want to know the ups and downs of any AV app, Reddit's always a good place to look – and the reaction to Supercut in r/visionpro has been positive, no doubt partly because Privitelli, the developer, has been cheerfully chatting with the other redditors in the subreddit and talking about what the app can do, can't do and what he hopes to do next. Future versions are likely to include some virtual viewing environments too. At just $4.99 for the app – roughly 1/700th of the cost of your Vision Pro – it's extremely affordable, and that means you'll happily forgive its shortcomings – such as the fairly basic Prime Video implementation. It delivers 4K, Dolby Atmos and Dolby Vision if your Netflix subscription includes them, and it supports multiple profiles for easy account switching. It'll also tell you what resolution you're getting and whether Dolby Atmos or Dolby Vision are happening. Supercut is available now in the App Store. You might also like Apple is restricting the potential of Vision Pro apps, but for a good reasonVision Pro put me on the MLS playoffs field and it was so realTwo days with Vision Pro: Apple's almost convinced me to part with $3,500 View the full article
-
As businesses across Europe look to stay ahead of the competition and drive success, leaders at these organizations are continuously on the lookout for new solutions. Especially those that tap into the potential of their data to generate valuable insights. A key innovation in this space growing in adoption is enhanced smart video that can lean on the power of artificial intelligence (AI). AI-powered smart video solutions have far more capabilities than the traditional surveillance associated with their basic counterparts, making these tools the new must have for businesses across numerous diverse sectors. They apply advanced analytics that deliver insights almost instantly to better operations, limit costs and boost revenue. A study from Western Digital was recently launched to understand the impact of AI on smart video, especially its capabilities for European businesses. The results found that AI is already integral in delivering advantages including improved scalability, efficiency, customization of surveillance and analytics. As smart video technology becomes more agile and AI grows in proliferation, its use cases will only increase further. While the full use cases of smart video are emerging, numerous examples can already be observed across diverse sectors including: Smart manufacturing: AI analytics in the factory In manufacturing, smart video is already critically important. When implemented in factories, these solutions carry various advantages. After filming the production process, leaders can collect data for analysis. Consequently, they can understand which stages of production are inefficient and then work to prevent bottlenecks. Data collected may also predict upcoming machinery issues, ensuring systems are upgraded as necessary. On a mass scale, improving production efficiency drives much greater outputs and profits. Beyond analytics generation, smart video technologies in factories can monitor employee health and safety, reporting on incidents automatically where appropriate. This can give factories access to better insurance policies and help to improve their reputation for staff welfare. In project management and planning, analytics from video recordings can also be referenced to align with global safety standards. Smart video in healthcare Hospitals, doctors’ surgeries and other healthcare facilities now increasingly rely on smart video systems to improve security and the efficiency of care. On entering a building, a patient’s data from smart video can trigger an alert, ensuring they patient receives care as quickly as possible. In some cases, this may come in the form of a staff member assisting them, or even a full team with specialist equipment during a medical emergency. Over weeks and months, data analytics can better facilities management and staffing levels, guaranteeing required resources are allocated to the peak times. This, therefore, limits unnecessary expenditure and staff burnout, especially prevalent if medical staff are in short supply. For example, if a GP surgery has too many staff in relation to patient appointments, smart video analytics can help identify busier facilities where staffing ought to be allocated. Keeping transport moving Smart video is also being used in public transport systems to improve service delivery. For companies managing trains, tubes, trams and buses, tracking journey times is a major operation. In London, the bus system alone is made up of 9,300 vehicles operating 675 routes. To boost efficiency, smart video insights can be used to assign staff and vehicles especially peak times when there is the greatest volume of human traffic. These insights can also be used to flag and counter issues. In some of the world’s largest cities, smart video insights can help a passenger in need of assistance, or a fault on a line. Where problems cause delays, analytics can help to reroute other trains where needed and alert control rooms to plan accordingly. This helps the world’s biggest cities to keep moving. Besides public transport, smart video is also being implemented for traffic management of roads in cities. When crossing a road, traffic lights will automatically change when necessary without the need to push a button. This ensures that these lights are being used most effectively. Insights from AI smart video can also be used to warn for upcoming traffic through signage changes, allowing drivers to re-route their journey to less congested routes. Data produced through smart video Research has highlighted the benefits of smart video, as well as an increasing willingness to install new or upgrade old smart video systems. However, rapid deployment will further increase demands to store valuable data. Most AI-equipped smart video solutions use 4K recording for real-time insights. Therefore, even more data must be stored and accessed on demand. As a quarter of businesses plan to implement this technology by the end of the year, data storage requirements will only increase. Depending on the scale of the smart video operations and specific user requirements, different storage solutions may be required. For the heavy workloads required to deal with video footage and analytics, many business leaders opt for HDDs as a cost-effective, high-capacity option. With the high performance required for these use cases, many business leaders opt for storage solutions specifically designed with smart video in mind. This helps organizations to work smarter. We've listed the best video conferencing software. This article was produced as part of TechRadarPro's Expert Insights channel where we feature the best and brightest minds in the technology industry today. The views expressed here are those of the author and are not necessarily those of TechRadarPro or Future plc. If you are interested in contributing find out more here: https://www.techradar.com/news/submit-your-story-to-techradar-pro View the full article
-
 Videos are full of valuable information, but tools are often needed to help find it. From educational institutions seeking to analyze lectures and tutorials to businesses aiming to understand customer sentiment in video reviews, transcribing and understanding video content is crucial for informed decision-making and innovation. Recently, advancements in AI/ML technologies have made this task more accessible than ever. Developing GenAI technologies with Docker opens up endless possibilities for unlocking insights from video content. By leveraging transcription, embeddings, and large language models (LLMs), organizations can gain deeper understanding and make informed decisions using diverse and raw data such as videos. In this article, we’ll dive into a video transcription and chat project that leverages the GenAI Stack, along with seamless integration provided by Docker, to streamline video content processing and understanding. High-level architecture The application’s architecture is designed to facilitate efficient processing and analysis of video content, leveraging cutting-edge AI technologies and containerization for scalability and flexibility. Figure 1 shows an overview of the architecture, which uses Pinecone to store and retrieve the embeddings of video transcriptions. Figure 1: Schematic diagram outlining a two-component system for processing and interacting with video data. The application’s high-level service architecture includes the following: yt-whisper: A local service, run by Docker Compose, that interacts with the remote OpenAI and Pinecone services. Whisper is an automatic speech recognition (ASR) system developed by OpenAI, representing a significant milestone in AI-driven speech processing. Trained on an extensive dataset of 680,000 hours of multilingual and multitask supervised data sourced from the web, Whisper demonstrates remarkable robustness and accuracy in English speech recognition. Dockerbot: A local service, run by Docker Compose, that interacts with the remote OpenAI and Pinecone services. The service takes the question of a user, computes a corresponding embedding, and then finds the most relevant transcriptions in the video knowledge database. The transcriptions are then presented to an LLM, which takes the transcriptions and the question and tries to provide an answer based on this information. OpenAI: The OpenAI API provides an LLM service, which is known for its cutting-edge AI and machine learning technologies. In this application, OpenAI’s technology is used to generate transcriptions from audio (using the Whisper model) and to create embeddings for text data, as well as to generate responses to user queries (using GPT and chat completions). Pinecone: A vector database service optimized for similarity search, used for building and deploying large-scale vector search applications. In this application, Pinecone is employed to store and retrieve the embeddings of video transcriptions, enabling efficient and relevant search functionality within the application based on user queries. Getting started To get started, complete the following steps: Create an OpenAI API Key. Ensure that you have a Pinecone API Key. Ensure that you have installed the latest version of Docker Desktop. The application is a chatbot that can answer questions from a video. Additionally, it provides timestamps from the video that can help you find the sources used to answer your question. Clone the repository The next step is to clone the repository: git clone https://github.com/dockersamples/docker-genai.git The project contains the following directories and files: ├── docker-genai/ │ ├── docker-bot/ │ ├── yt-whisper/ │ ├── .env.example │ ├── .gitignore │ ├── LICENSE │ ├── README.md │ └── docker-compose.yaml Specify your API keys In the /docker-genai directory, create a text file called .env, and specify your API keys inside. The following snippet shows the contents of the .env.example file that you can refer to as an example. #------------------------------------------------------------- # OpenAI #------------------------------------------------------------- OPENAI_TOKEN=your-api-key # Replace your-api-key with your personal API key #------------------------------------------------------------- # Pinecone #-------------------------------------------------------------- PINECONE_TOKEN=your-api-key # Replace your-api-key with your personal API key Build and run the application In a terminal, change directory to your docker-genai directory and run the following command: docker compose up --build Next, Docker Compose builds and runs the application based on the services defined in the docker-compose.yaml file. When the application is running, you’ll see the logs of two services in the terminal. In the logs, you’ll see the services are exposed on ports 8503 and 8504. The two services are complementary to each other. The yt-whisper service is running on port 8503. This service feeds the Pinecone database with videos that you want to archive in your knowledge database. The next section explores the yt-whisper service. Using yt-whisper The yt-whisper service is a YouTube video processing service that uses the OpenAI Whisper model to generate transcriptions of videos and stores them in a Pinecone database. The following steps outline how to use the service. Open a browser and access the yt-whisper service at http://localhost:8503. Once the application appears, specify a YouTube video URL in the URL field and select Submit. The example shown in Figure 2 uses a video from David Cardozo. Figure 2: A web interface showcasing processed video content with a feature to download transcriptions. Submitting a video The yt-whisper service downloads the audio of the video, then uses Whisper to transcribe it into a WebVTT (*.vtt) format (which you can download). Next, it uses the “text-embedding-3-small” model to create embeddings and finally uploads those embeddings into the Pinecone database. After the video is processed, a video list appears in the web app that informs you which videos have been indexed in Pinecone. It also provides a button to download the transcript. Accessing Dockerbot chat service You can now access the Dockerbot chat service on port 8504 and ask questions about the videos as shown in Figure 3. Figure 3: Example of a user asking Dockerbot about NVIDIA containers and the application giving a response with links to specific timestamps in the video. Conclusion In this article, we explored the exciting potential of GenAI technologies combined with Docker for unlocking valuable insights from video content. It shows how the integration of cutting-edge AI models like Whisper, coupled with efficient database solutions like Pinecone, empowers organizations to transform raw video data into actionable knowledge. Whether you’re an experienced developer or just starting to explore the world of AI, the provided resources and code make it simple to embark on your own video-understanding projects. Learn more Accelerated AI/ML with Docker Build and run natural language processing (NLP) applications with Docker Video transcription and chat using GenAI Stack PDF analysis and chat using GenAI Stack Subscribe to the Docker Newsletter. Have questions? The Docker community is here to help. View the full article
Videos are full of valuable information, but tools are often needed to help find it. From educational institutions seeking to analyze lectures and tutorials to businesses aiming to understand customer sentiment in video reviews, transcribing and understanding video content is crucial for informed decision-making and innovation. Recently, advancements in AI/ML technologies have made this task more accessible than ever. Developing GenAI technologies with Docker opens up endless possibilities for unlocking insights from video content. By leveraging transcription, embeddings, and large language models (LLMs), organizations can gain deeper understanding and make informed decisions using diverse and raw data such as videos. In this article, we’ll dive into a video transcription and chat project that leverages the GenAI Stack, along with seamless integration provided by Docker, to streamline video content processing and understanding. High-level architecture The application’s architecture is designed to facilitate efficient processing and analysis of video content, leveraging cutting-edge AI technologies and containerization for scalability and flexibility. Figure 1 shows an overview of the architecture, which uses Pinecone to store and retrieve the embeddings of video transcriptions. Figure 1: Schematic diagram outlining a two-component system for processing and interacting with video data. The application’s high-level service architecture includes the following: yt-whisper: A local service, run by Docker Compose, that interacts with the remote OpenAI and Pinecone services. Whisper is an automatic speech recognition (ASR) system developed by OpenAI, representing a significant milestone in AI-driven speech processing. Trained on an extensive dataset of 680,000 hours of multilingual and multitask supervised data sourced from the web, Whisper demonstrates remarkable robustness and accuracy in English speech recognition. Dockerbot: A local service, run by Docker Compose, that interacts with the remote OpenAI and Pinecone services. The service takes the question of a user, computes a corresponding embedding, and then finds the most relevant transcriptions in the video knowledge database. The transcriptions are then presented to an LLM, which takes the transcriptions and the question and tries to provide an answer based on this information. OpenAI: The OpenAI API provides an LLM service, which is known for its cutting-edge AI and machine learning technologies. In this application, OpenAI’s technology is used to generate transcriptions from audio (using the Whisper model) and to create embeddings for text data, as well as to generate responses to user queries (using GPT and chat completions). Pinecone: A vector database service optimized for similarity search, used for building and deploying large-scale vector search applications. In this application, Pinecone is employed to store and retrieve the embeddings of video transcriptions, enabling efficient and relevant search functionality within the application based on user queries. Getting started To get started, complete the following steps: Create an OpenAI API Key. Ensure that you have a Pinecone API Key. Ensure that you have installed the latest version of Docker Desktop. The application is a chatbot that can answer questions from a video. Additionally, it provides timestamps from the video that can help you find the sources used to answer your question. Clone the repository The next step is to clone the repository: git clone https://github.com/dockersamples/docker-genai.git The project contains the following directories and files: ├── docker-genai/ │ ├── docker-bot/ │ ├── yt-whisper/ │ ├── .env.example │ ├── .gitignore │ ├── LICENSE │ ├── README.md │ └── docker-compose.yaml Specify your API keys In the /docker-genai directory, create a text file called .env, and specify your API keys inside. The following snippet shows the contents of the .env.example file that you can refer to as an example. #------------------------------------------------------------- # OpenAI #------------------------------------------------------------- OPENAI_TOKEN=your-api-key # Replace your-api-key with your personal API key #------------------------------------------------------------- # Pinecone #-------------------------------------------------------------- PINECONE_TOKEN=your-api-key # Replace your-api-key with your personal API key Build and run the application In a terminal, change directory to your docker-genai directory and run the following command: docker compose up --build Next, Docker Compose builds and runs the application based on the services defined in the docker-compose.yaml file. When the application is running, you’ll see the logs of two services in the terminal. In the logs, you’ll see the services are exposed on ports 8503 and 8504. The two services are complementary to each other. The yt-whisper service is running on port 8503. This service feeds the Pinecone database with videos that you want to archive in your knowledge database. The next section explores the yt-whisper service. Using yt-whisper The yt-whisper service is a YouTube video processing service that uses the OpenAI Whisper model to generate transcriptions of videos and stores them in a Pinecone database. The following steps outline how to use the service. Open a browser and access the yt-whisper service at http://localhost:8503. Once the application appears, specify a YouTube video URL in the URL field and select Submit. The example shown in Figure 2 uses a video from David Cardozo. Figure 2: A web interface showcasing processed video content with a feature to download transcriptions. Submitting a video The yt-whisper service downloads the audio of the video, then uses Whisper to transcribe it into a WebVTT (*.vtt) format (which you can download). Next, it uses the “text-embedding-3-small” model to create embeddings and finally uploads those embeddings into the Pinecone database. After the video is processed, a video list appears in the web app that informs you which videos have been indexed in Pinecone. It also provides a button to download the transcript. Accessing Dockerbot chat service You can now access the Dockerbot chat service on port 8504 and ask questions about the videos as shown in Figure 3. Figure 3: Example of a user asking Dockerbot about NVIDIA containers and the application giving a response with links to specific timestamps in the video. Conclusion In this article, we explored the exciting potential of GenAI technologies combined with Docker for unlocking valuable insights from video content. It shows how the integration of cutting-edge AI models like Whisper, coupled with efficient database solutions like Pinecone, empowers organizations to transform raw video data into actionable knowledge. Whether you’re an experienced developer or just starting to explore the world of AI, the provided resources and code make it simple to embark on your own video-understanding projects. Learn more Accelerated AI/ML with Docker Build and run natural language processing (NLP) applications with Docker Video transcription and chat using GenAI Stack PDF analysis and chat using GenAI Stack Subscribe to the Docker Newsletter. Have questions? The Docker community is here to help. View the full article -
I’ve been increasingly driven to distraction by YouTube’s ever-more-aggressive delivery of adverts before, during and after videos, which is making it a challenge to even get to the bits of a video that I want to see without having some earnest voice encourage me to trade stocks or go to Dubai. Until now I’ve been too cheap to subscribe to YouTube Premium – but that may soon change. That’s because YouTube is apparently testing an AI-powered recommendation system that will analyze patterns in viewer behavior to cleverly skip to the most popular parts of a video with just a double tap on a touchscreen. “The way it works is, if a viewer is double tapping to skip ahead on an eligible segment, we’ll show a jump ahead button that will take them to the next point in the video that we think they’re aiming for,” YouTube creator-centric channel Creator Insider explained. “This feature will also be available to creators while watching their own videos.” Currently, such a double-tap action skips a YouTube video forward by a few seconds, which I don’t find hugely useful. And while YouTube introduces a form of wave pattern on the video timeline to show what the most popular parts of the video are, it’s not the easiest thing to use, and can sometimes feel rather lacking in intuitiveness. So being able to easily tap to get to the most popular part of a video, at least according to an AI, could be a boon for impatient people like me. The only wrinkle is that this feature is only being tested for YouTube Premium users, and is currently limited to the US. But such features do tend to get a larger global rollout once they come out of the testing phase, meaning there’s scope for Brits like myself to have access to some smart double-tap video skipping – that’s if I do finally decide to bite the bullet and pay for YouTube Premium. You might also like Disney Plus free trial: can you still get one?Netflix's 3 Body Problem was ready to go in mid-2023, but it was held back for one big reasonWant to beat TV reflections? Here are the different types, and how to stop them View the full article
-
Video encoding and transcoding are critical workloads for media and entertainment companies. Delivering high-quality video content to viewers across devices and networks needs efficient and scalable encoding infrastructure. As video resolutions continue to increase to 4K and 8K, GPU acceleration is essential to real-time encoding workflows where parallel encoding tasks are necessary. Although encoding on the CPU is possible, this is better suited to smaller-scale sequential encoding tasks or where encoding speed is less of a concern. AWS offers GPU instance families, such as G4dn, G5, and G5g, which are well suited for these real-time encoding workloads. Modern GPUs offer users thousands of shading units and the ability to process billions of pixels per second. Running a single encoding job on the GPU often leaves resources under-used, which presents an optimization opportunity. By running multiple processes simultaneously on a single GPU, processes can be bin-packed and use a fraction of the GPU. This practice is known as fractionalization. This post explores how to build a video encoding pipeline on AWS that uses fractional GPUs in containers using Amazon Elastic Kubernetes Service (Amazon EKS). By splitting the GPU into fractions, multiple encoding jobs can share the GPU concurrently. This improves resource use and lowers costs. This post also looks at using Bottlerocket and Karpenter to achieve fast scaling of heterogeneous encoding capacity. With Bottlerocket’s image caching capabilities, new instances can start-up rapidly to handle spikes in demand. By combining fractional GPUs, containers, and Bottlerocket on AWS, media companies can achieve the performance, efficiency, and scale they need for delivering high-quality video streams to viewers. The examples in this post are using the following software versions: Amazon EKS version 1.28 Karpenter version 0.33.0 Bottlerocket version 1.16.0 To view and deploy the full example, see the GitHub repository. Configuring GPU time-slicing in Amazon EKS The concept of sharing or time-slicing a GPU is not new. To achieve maximum use, multiple processes can be run on the same physical GPU. By using as much of the available GPU capacity as possible, the cost per streaming session decreases. Therefore, the density – the number of simultaneous transcoding or encoding processes – is an important dimension for cost-effective media-streaming. With the popularity of Kubernetes, GPU vendors have invested heavily in developing plugins to make this process easier. Some of benefits of using Kubernetes over running processes directly on the virtual machine (VM) are: Resiliency – By using Kubernetes daemonsets and deployments, you can rely on Kubernetes to automatically restart any crashed or failed tasks. Security – Network policies can be defined to prevent inter-pod communication. Additionally, Kubernetes namespaces can be used to provide additional isolation. This is useful in multi-tenant environments for software-vendors and Software-as-a-Service (SaaS) providers. Elasticity – Kubernetes deployments allow you to easily scale-out and scale-in based on changing traffic volumes. Event-driven autoscaling, such as with KEDA, allows for responsive provisioning of additional resources. Tools such as the Cluster Autoscaler and Karpenter automatically provision compute capacity based on resource use. A device plugin is needed to expose the GPU resources to Kubernetes. It is the device plugin’s primary job to make the details of the available GPU resources visible to Kubernetes. Multiple plugins are available for allocating fractions of GPU in Kubernetes. In this post, the NVIDIA device plugin for Kubernetes is used as it provides a lightweight mechanism to expose the GPU resources. As of version 12 this plugin supports time-slicing. Additional wrappers for the device plugin are available, such as the NVIDIA GPU Operator for Kubernetes, which provide further management and monitoring capabilities if needed. To configure the NVIDIA device plugin with time-slicing, the following steps should be followed. Remove any existing NVIDIA device plugin from the cluster: kubectl delete daemonset nvidia-device-plugin-daemonset -n kube-system Next, create a ConfigMap to define how many “slices” to split the GPU into. The number of slices needed can be calculated by reviewing the GPU use for a single task. For example, if your workload uses at most 10% of the available GPU, you could split the GPU into 10 slices. This is shown in the following example config: apiVersion: v1 kind: ConfigMap metadata: name: time-slicing-config-all data: any: |- version: v1 flags: migStrategy: none sharing: timeSlicing: resources: - name: nvidia.com/gpu replicas: 10 kubectl create -n kube-system -f time-slicing-config-all.yaml Finally, deploy the latest version of the plugin, using the created ConfigMap: helm repo add nvdp https://nvidia.github.io/k8s-device-plugin helm repo update helm upgrade -i nvdp nvdp/nvidia-device-plugin \ --version=0.14.1 \ --namespace kube-system \ --create-namespace \ --set config.name=time-slicing-config-all If the nodes in the cluster are inspected, then they show an updated GPU resource limit, despite only having one physical GPU: Capacity: cpu: 8 ephemeral-storage: 104845292Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 32386544Ki nvidia.com/gpu: 10 pods: 29 As the goal is to bin-pack as many tasks on to a single GPU as possible, it is likely the Max Pods setting are hit next. On the machine used in this post (g4dn.2xlarge) the default max pods is 29. For testing purposes, this is increased to 110 pods. 110 is the maximum recommended for nodes smaller than 32 vCPUs. To increase this, the following steps need to be followed. Pass the max-pods flag to the kubelet in the node bootstrap script: /etc/eks/bootstrap.sh my-cluster --use-max-pods false --kubelet-extra-args '--max-pods=110' When using Karpenter for auto-scaling, the NodePool resource definition passes this configuration to new nodes: kubelet: maxPods: 110 The number of pods is now limited by the maximum Elastic Network Interfaces (ENIs) and IP addresses per interface. See the ENI documentation for the limits for each instance type. The formula is Number of ENIs * (Number of IPv4 per ENI – 1) + 2). To increase the max pods per node beyond this, prefix delegation must be used. This is configured using the following command: kubectl set env daemonset aws-node -n kube-system ENABLE_PREFIX_DELEGATION=true For more details on prefix delegation, see Amazon VPC CNI increases pods per node limits. Amazon EC2 instance type session density The next decision is which instance type to use. GPU instances are often in high demand because of their use in both Media and Machine Learning (ML) workloads. It is a best practice to diversify across as many instance types as you can in all the Availability Zones (AZs) in an AWS Region. At the time of writing, the three current generation NVIDIA GPU-powered instance families most used for Media workloads are G4dn, G5, and G5g. The latter uses an ARM64 CPU architecture with AWS Graviton 2 processors. The examples used in the post use 1080p25 (1080 resolution and 25 frames-per-second) as the frame-rate profile. If you are using a different resolution or framerate, then your results vary. To test this, ffmpeg was run in the container using h264 hardware encoding with CUDA using the following arguments: ffmpeg -nostdin -y -re -vsync 0 -c:v h264_cuvid -hwaccel cuda -i <input_file> -c:v h264_nvenc -preset p1 -profile:v baseline -b:v 5M -an -f rtp -payload_type 98 rtp://192.168.58.252:5000?pkt_size=1316 The key options used in this example are as follows, and you may want to change these based on your requirements: `-re`: Read input at the native frame rate. This is particularly useful for real-time streaming scenarios. `-c:v h264_cuvid`: Use NVIDIA CUVID for decoding. `-hwaccel cuda`: Specify CUDA as the hardware acceleration API. `-c:v h264_nvenc`: Use NVIDIA NVENC for video encoding. `-preset p1`: Set the encoding preset to “p1” (you might want to adjust this based on your requirements). `-profile:v baseline`: Set the H.264 profile to baseline. `-b:v 5M`: Set the video bitrate to 5 Mbps. To view the full deployment definition, see the GitHub repository. All instances were using NVIDIA driver version 535 and CUDA version 12.2. Then, the output was monitored on a remote instance using the following command: ffmpeg -protocol_whitelist file,crypto,udp,rtp -i input.sdp -f null – Concurrent Sessions Average g4dn.2xlarge FPS Average g5g.2xlarge FPS Average g5.2xlarge FPS 26 25 25 25 27 25 25 25 28 25 25 25 29 23 24 25 30 23 24 25 31 23 23 25 32 22 23 24 33 22 21 23 35 21 20 22 40 19 19 19 50 12 12 15 The green highlighted cells indicate the maximum concurrent sessions at which the desired framerate was consistently achieved. G4dn.2xlarge The T4 GPU in the g4dn instance has a single encoder, which means that the encoder consistently reaches capacity at around 28 concurrent jobs. On a 2xl, there is still spare VRAM, CPU, and memory available at this density. This spare capacity could be used to encode additional sessions on the CPU, run the application pods, or the instance could be scaled down to a smaller instance size. Besides monitoring the FPS, the stream can be manually monitored using ffplay or VLC. Note that although additional sessions can be run beyond the preceding numbers, frame rate drops become more common. Eventually, the GPU becomes saturated and CUDA memory exceptions are thrown, causing the container to crash and restart. The following stream quality was observed when manually watching the stream through VLC: 25-28 sessions – high quality, minimal drops in frame rate, optimal viewing experience >=30 sessions – some noticeable drops in frame rate and resolution. >=50 sessions – frequent stutters, and heavy artifacts, mostly unwatchable (at this density CPU, Memory and Network could all become bottlenecks) G5g.2xlarge The Graviton-based instance performs nearly identically to the G4dn. This is expected as the T4g GPU in the G5g instance has similar specifications to the T4 GPU. The key difference is that the G5g uses ARM-based Graviton 2 processors instead of x86. This means the G5g instances have approximately 25% better price/performance than the equivalent G4dn. When deploying ffmpeg in a containerized environment, this means that multi-arch container images can be built to target both x86 and ARM architectures. Using hardware encoding with h264 and CUDA works well using cross-compiled libraries for ARM. G5.2xlarge The G5 instances use the newer A10G GPU. This adds an additional 8GB of VRAM and doubles the memory bandwidth compared to the T4, up to 600 GBs thanks to PCIe Gen4. This means it can produce lower latency, higher resolution video. However, it still has one encoder. When running concurrent rendering jobs, the bottleneck is the encoder capacity. The higher memory bandwidth allows a couple of extra concurrent sessions, but the density that can be achieved is similar. This does mean it is possible to achieve the same density at a slightly higher framerate or resolution. The cost per session for each instance is shown in the following table (based on on-demand pricing in the US-East-1 Region): Instance Type Cost per hour ($) Max sessions at 1080p25 Cost per session per hour ($) G4dn 0.752 28 0.027 G5 1.212 31 0.039 G5g 0.556 28 0.02 By mixing different instance families and sizes and deploying across all AZs in a Region or multiple Regions, you can improve your resiliency and scalability. This also allows you to unlock the maximum spot discount by choosing a “price-capacity-optimized” model if your application is able to gracefully handle spot interruptions. Horizontal node auto-scaling As media-streaming workloads fluctuate with viewing habits, it’s important to have elastically scalable rendering capacity. The more responsively additional compute capacity can be provisioned, the better the user experience. This also optimizes the cost by reducing the need to provision for peak. Note that this section explores scaling of the underlying compute resources, not auto-scaling the workloads themselves. The latter is covered in the Horizontal Pod Autoscaler documentation. Container images needing video drivers or frameworks are often large, typically ranging from 500MiB – 3GiB+. Fetching these large container images over the network can be time intensive. This impairs the ability to scale responsively to sudden changes in activity. There are some tools that can be leveraged to make scaling more responsive: Karpenter – Karpenter allows for scaling using heterogeneous instance types. This means pools of G4dn, G5, and G5g instances can be used, with Karpenter picking the most cost effective to place the pending pods. As the resource type used by the device plugin presents as a standard GPU resource, Karpenter can scale based on this resource. As of writing, Karpenter does not support scaling based on custom resources. Initially nodes are launched with the default one GPU resource until the node is properly labelled by the device plugin. During spikes in scaling, nodes may be over-provisioned until Karpenter reconciles the workload. Bottlerocket – Bottlerocket is a minimal container OS that only contains the software needed to run container images. Due to this smaller footprint, Bottlerocket nodes can start faster than general-purpose Linux distributions in some scenarios, see the following table for a comparison of this: Stage General-purpose Linux elapsed time g4dn.xlarge (s) Bottlerocket elapsed time g4dn.xlarge (s) Bottlerocket elapsed time g5g.xlarge (s) Instance Launch 0 0 0 Kubelet Starting 33.36 17.5 16.54 Kubelet Started 37.36 21.25 19.85 Node Ready 51.71 34.19 32.38 Caching container images on the node. When using Bottlerocket, container images are read from the data volume. This data volume is initialized on instance boot. This means that container images can be pre-fetched or cached onto an Amazon Elastic Block Store (Amazon EBS) volume, rather than pulled over the network. This can lead to considerably faster node start times. For a detailed walkthrough of this process, see Reduce container startup time on Amazon EKS with Bottlerocket data volume. As an additional scaling technique, the cluster can be over-provisioned. Having an additional warm pool of nodes available for scheduling allows for sudden spikes while the chosen autoscaling configuration kicks in. This is explored in more detail in Eliminate Kubernetes node scaling lag with pod priority and over-provisioning. By using a multi-arch container build, multiple Amazon Elastic Compute Cloud (Amazon EC2) instance types can be targeted using the same NodePool configuration in Karpenter. This allows for cost-effective scaling of resources. The example workload was built using the following command: docker buildx build --platform "linux/amd64,linux/arm64" --tag ${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_DEFAULT_REGION}.amazonaws.com/ffmpeg:1.0 --push . -f Dockerfile This allows for a NodePool defined in Karpenter as follows: apiVersion: karpenter.sh/v1beta1 kind: NodePool metadata: name: default spec: template: spec: requirements: - key: karpenter.sh/capacity-type operator: In values: ["on-demand", "spot"] - key: "node.kubernetes.io/instance-type" operator: In values: ["g5g.2xlarge", "g4dn.2xlarge", "g5.2xlarge"] nodeClassRef: name: default kubelet: maxPods: 110 In this NodePool, all three instance types are available for Karpenter to use. Karpenter can choose the most efficient, regardless of processor architecture, as we are using the multi-arch image built previously in the deployment. The capacity type uses spot instances to reduce cost. If the workload cannot tolerate interruptions, then spot can be removed and only on-demand instances are provisioned. This would work with any supported operating system. To make Karpenter use Bottlerocket-based Amazon Machine Images (AMIs), the corresponding EC2NodeClass is defined as follows: apiVersion: karpenter.k8s.aws/v1beta1 kind: EC2NodeClass metadata: name: default spec: amiFamily: Bottlerocket ... This automatically selects the latest AMI in the specified family, in this case Bottlerocket. For the full example and more details on this configuration, see the example in the GitHub repository. Conclusion By leveraging fractional GPUs, container orchestration, and purpose-built OS and instance types, media companies can achieve up to 95% better price-performance. The techniques covered in this post showcase how AWS infrastructure can be tailored to deliver high density video encoding at scale. With thoughtful architecture decisions, organizations can future-proof their workflows and provide exceptional viewing experiences as video continues evolving to higher resolutions and bitrates. To start optimizing your workloads, experiment with different instance types and OS options such as Bottlerocket. Monitor performance and cost savings as you scale out encoding capacity. Use AWS’s flexibility and purpose-built tools to future-proof your video pipeline today. View the full article
-
Amazon Interactive Video Service (Amazon IVS) web broadcast SDK gives you the ability to capture live video from web browsers and send as an input to an Amazon IVS channel. You can include it on new and existing websites, with support for both desktop and mobile web browsers. View the full article
-
The Amazon Chime SDK now supports up to 100 webcam video streams per WebRTC session. The Amazon Chime SDK lets developers add intelligent real-time audio, video, and screen share to their web and mobile applications. Each client application can select up to 25 webcam video streams to display, enabling developers to create immersive video experiences that are bespoke for each user. View the full article
-
We are excited to announce that the Amazon EC2 VT1 instances now support the AMD-Xilinx Video SDK 2.0, bringing support for Gstreamer, 10-bit HDR video, and dynamic encoder parameters. In addition to new features, this new version offers improved visual quality for 4k video, support for a newer version of FFmpeg (4.4), expanded OS/kernel support, and bug fixes. View the full article
-
Video on Demand on AWS Foundation solution provisions the AWS services required to build scalable, distributed VOD processing and delivery workflows. This solution is designed to help you quickly get started encoding video files with AWS Elemental MediaConvert. It can be easily customized and used as the starting point to create a more complex workflow. View the full article
-
 We are thrilled to announce that MediaOps is the recipient of two Hermes Creative Awards. TechStrong TV won the Gold Award in the video/informational category and DevOps Chats won the Gold Award for audio/podcast series. The Hermes Creative Awards is an international competition for creative professionals involved in the concept, writing and design of traditional […] View the full article
We are thrilled to announce that MediaOps is the recipient of two Hermes Creative Awards. TechStrong TV won the Gold Award in the video/informational category and DevOps Chats won the Gold Award for audio/podcast series. The Hermes Creative Awards is an international competition for creative professionals involved in the concept, writing and design of traditional […] View the full article -
.thumb.png.76bbad720e2b8f6c056f54fb105215de.png) In June 2020, we announced the preview of the Live Video Analytics platform—a groundbreaking new set of capabilities in Azure Media Services that allows you to build workflows that capture and process video with real-time analytics from the intelligent edge to intelligent cloud. We continue to see customers across industries enthusiastically using Live Video Analytics on IoT Edge in preview, to drive positive outcomes for their organizations. Last week at Microsoft Ignite, we announced new features, partner integrations, and reference apps that unlock additional scenarios that include social distancing, factory floor safety, security perimeter monitoring, and more. The new product capabilities that enable these scenarios include: Spatial Analysis in Azure Computer Vision for Cognitive Services: Enhanced video analytics that factor in the spatial relationships between people and movement in the physical domain. Intel OpenVINO Model Server integration: Build complex, highly performant live video analytics solutions powered by OpenVINO toolkit, with optimized pre-trained models running on Intel CPUs (Atom, Core, Xeon), FPGAs, and VPUs. NVIDIA DeepStream integration: Support for hardware accelerated hybrid video analytics apps that combine the power of NVIDIA GPUs with Azure services. Arm64 support: Develop and deploy live video analytics solutions on low power, low footprint Linux Arm64 devices. Azure IoT Central Custom Vision Template: Build rich custom vision applications in as little as a few minutes to a few hours with no coding required. High frame rate inferencing with Cognitive Services Custom Vision integration: Demonstrated in a manufacturing industry reference app that supports six useful out of the box scenarios for factory environments. Making video AI easier to use Given the wide array of available CPU architectures (x86-64, Arm, and more) and hardware acceleration options (Intel Movidius VPU, iGPU, FPGA, NVIDIA GPU), plus the dearth of data science professionals to build customized AI, putting together a traditional video analytics solution entails significant time, effort and complexity. The announcements we’re making today further our mission of making video analytics more accessible and useful for everyone—with support for widely used chip architectures, including Intel, NVIDIA and Arm, integration with hardware optimized AI frameworks like NVIDIA DeepStream and Intel OpenVINO, closer integration with complementary technologies across Microsoft’s AI ecosystem—Computer Vision for Spatial Analysis and Cognitive Services Custom Vision, as well as an improved development experience via the Azure IoT Central Custom Vision template and a manufacturing floor reference application. Live video analytics with Computer Vision for Spatial Analysis The Spatial Analysis capability of Computer vision, a part of Azure Cognitive Service, can be used in conjunction with Live Video Analytics on IoT Edge to better understand the spatial relationships between people and movement in physical environments. We’ve added new operations that enable you to count people in a designated zone within the camera’s field of view, to track when a person crosses a designated line or area, or when people violate a distance rule. The Live Video Analytics module will capture live video from real-time streaming protocol (RTSP) cameras and invoke the spatial analysis module for AI processing. These modules can be configured to enable video analysis and the recording of clips locally or to Azure Blob storage. Deploying the Live Video Analytics and the Spatial Analysis modules on edge devices is made easier by Azure IoT Hub. Our recommended edge device is Azure Stack Edge with the NVIDIA T4 Tensor Core GPU. You can learn more about how to analyze live video with Computer Vision for Spatial Analysis in our documentation. Live Video Analytics with Intel’s OpenVINO Model Server You can pair the Live Video Analytics on IoT Edge module with the OpenVINO Model Server(OVMS) – AI Extension from Intel to build complex, highly performant live video analytics solutions. Open vehicle monitoring system (OVMS) is an inference server powered by the OpenVINO toolkit that’s highly optimized for computer vision workloads running on Intel. As an extension, HTTP support and samples have been added to OVMS to facilitate the easy exchange of video frames and inference results between the inference server and the Live Video Analytics module, empowering you to run any object detection, classification or segmentation models supported by OpenVINO toolkit. You can customize the inference server module to use any optimized pre-trained models in the Open Model Zoo repository, and select from a wide variety of acceleration mechanisms supported by Intel hardware without having to change your application, including CPUs (Atom, Core, Xeon), field programmable gate arrays (FPGAs), and vision processing units (VPUs) that best suit your use case. In addition, you can select from a wide variety of use case-specific Intel-based solutions such as Developer Kits or Market Ready Solutions and incorporate easily pluggable Live Video Analytics platform for scale. “We are delighted to unleash the power of AI at the edge by extending OpenVINO Model Server for Azure Live Video Analytics. This extension will simplify the process of developing complex video solutions through a modular analytics platform. Developers are empowered to quickly build their edge to cloud applications once and deploy to Intel’s broad range of compute and AI accelerator platforms through our rich ecosystems.”—Adam Burns, VP, Edge AI Developer Tools, Internet of Things Group, Intel Live Video Analytics with NVIDIA’s DeepStream SDK Live Video Analytics and NVIDIA DeepStream SDK can be used to build hardware-accelerated AI video analytics apps that combine the power of NVIDIA graphic processing units (GPUs) with Azure cloud services, such as Azure Media Services, Azure Storage, Azure IoT, and more. You can build sophisticated real-time apps that can scale across thousands of locations and can manage the video workflows on the edge devices at those locations via the cloud. You can explore some related samples on GitHub. You can use Live Video Analytics to build video workflows that span the edge and cloud, and then combine DeepStream SDK to build pipelines to extract insights from video using the AI of your choice. The diagram above illustrates how you can record video clips that are triggered by AI events to Azure Media Services in the cloud. The samples are a testament to robust design and openness of both platforms. “The powerful combination of NVIDIA DeepStream SDK and Live Video Analytics powered by the NVIDIA computing stack helps accelerate the development and deployment of world-class video analytics. Our partnership with Microsoft will advance adoption of AI-enabled video analytics from edge to cloud across all industries and use cases.”—Deepu Talla, Vice President and General Manager of Edge Computing, NVIDIA Live Video Analytics now runs on Arm You can now run Live Video Analytics on IoT Edge on Linux Arm64v8 devices, enabling you to use low power-consumption, low-footprint devices such as the NVIDIA® Jetson™ series. Develop Solutions Rapidly Using the IoT Central Video Analytics Template The new IoT Central video analytics template simplifies the setup of an Azure IoT Edge device to act as a gateway between cameras and Azure cloud services. It integrates the Azure Live Video analytics video inferencing pipeline and OpenVINO Model Server—an AI Inference server by Intel, enabling customers to build a fully working end-to-end solution in a couple of hours with no code. It’s fully integrated with the Azure Media Services pipeline to capture, record, and play analyzed videos from the cloud. The template installs IoT Edge modules such as an IoT Central Gateway, Live Video Analytics on IoT Edge, Intel OpenVINO Model server, and an ONVIF module on your edge devices. These modules help the IoT Central application configure and manage the devices, ingest live video streams from the cameras, and easily apply AI models such as vehicle or person detection. Simultaneously in the cloud, Azure Media Services and Azure Storage record and stream relevant portions of the live video feed. Refer to our IoT Show episode and related blog post for a full overview and guidance on how to get started. Integration of Cognitive Services Custom Vision models in Live Video Analytics Many organizations already have a large number of cameras deployed to capture video data but are not conducting any meaningful analysis on the streams. With the advent of Live Video Analytics, applying even basic image classification and object detection algorithms to live video feeds can help unlock truly useful insights and make businesses safer, more secure, more efficient, and ultimately more profitable. Potential scenarios include: Detecting if employees in an industrial/manufacturing plant are wearing hard hats to ensure their safety and compliance with local regulations. Counting products or detecting defective products on a conveyer belt. Detecting the presence of unwanted objects (people, vehicles, and more) on-premises and notifying security. Detecting low and out of stock products on retail store shelves or on factory parts shelves. Developing AI models from scratch to perform tasks like these and deploying them at scale to work on live video streams on the edge entails a non-trivial amount of work. Doing it in a scalable and reliable way is even harder and more expensive. The integration of Live Video Analytics on IoT Edge with Cognitive Services Custom Vision makes it possible to implement working solutions for all of these scenarios in a matter of minutes to a few hours. You begin by first building and training a computer vision model by uploading pre-labeled images to the Custom Vision service. This doesn’t require you to have any prior knowledge of data science, machine learning, or AI. Then, you can use Live Video Analytics to deploy the trained custom model as a container on the edge and analyze multiple camera streams in a cost-effective manner. Live Video Analytics powered manufacturing floor reference app We have partnered with the Azure Stack team to evolve the Factory.AI solution, a turn-key application that makes it easy to train and deploy vision models without the need for data science knowledge. The solution includes capabilities for object counting, employee safety, defect detection, machine misalignment, tool detection, and part confirmation. All these scenarios are powered by the integration of Live Video Analytics running on Azure Stack Edge devices. In addition, the Factory.AI solution also allows customers to train and deploy their own custom ONNX models using Custom Vision SDK. Once a custom model is deployed on the edge, the reference app leverages gRPC from Live Video Analytics for high frame rate accurate inferencing. You can learn more about the manufacturing reference app at Microsoft Ignite or by visiting the Azure intelligent edge patterns page. Get started today In closing, we’d like to thank everyone who is already participating in the Live Video Analytics on IoT Edge preview. We appreciate your ongoing feedback to our engineering team as we work together to fuel your success with video analytics both in the cloud and on the edge. For those of you who are new to our technology, we’d encourage you to get started today with these helpful resources: Watch the Live Video Analytics introduction video. Find more information on the product details page. Watch the Live Video Analytics demo. Try the new Live Video Analytics features today with an Azure free trial account. Register on the Media Services Tech Community and hear directly from the Engineering team on upcoming new features, to provide feedback and discuss roadmap requests. Download Live Video Analytics on IoT Edge from the Azure Marketplace. Get started quickly with our C# and Python code samples. Review our product documentation. Search the GitHub repo for Live Video Analytics open source projects. Contact amshelp@microsoft.com for questions. Intel, the Intel logo, Atom, Core, Xeon, and OpenVINO are registered trademarks of Intel Corporation or its subsidiaries. NVIDIA and the NVIDIA logo are registered trademarks or trademarks of NVIDIA Corporation in the U.S. and/or other countries. Other company and product names may be trademarks of the respective companies with which they are associated. View the full article
In June 2020, we announced the preview of the Live Video Analytics platform—a groundbreaking new set of capabilities in Azure Media Services that allows you to build workflows that capture and process video with real-time analytics from the intelligent edge to intelligent cloud. We continue to see customers across industries enthusiastically using Live Video Analytics on IoT Edge in preview, to drive positive outcomes for their organizations. Last week at Microsoft Ignite, we announced new features, partner integrations, and reference apps that unlock additional scenarios that include social distancing, factory floor safety, security perimeter monitoring, and more. The new product capabilities that enable these scenarios include: Spatial Analysis in Azure Computer Vision for Cognitive Services: Enhanced video analytics that factor in the spatial relationships between people and movement in the physical domain. Intel OpenVINO Model Server integration: Build complex, highly performant live video analytics solutions powered by OpenVINO toolkit, with optimized pre-trained models running on Intel CPUs (Atom, Core, Xeon), FPGAs, and VPUs. NVIDIA DeepStream integration: Support for hardware accelerated hybrid video analytics apps that combine the power of NVIDIA GPUs with Azure services. Arm64 support: Develop and deploy live video analytics solutions on low power, low footprint Linux Arm64 devices. Azure IoT Central Custom Vision Template: Build rich custom vision applications in as little as a few minutes to a few hours with no coding required. High frame rate inferencing with Cognitive Services Custom Vision integration: Demonstrated in a manufacturing industry reference app that supports six useful out of the box scenarios for factory environments. Making video AI easier to use Given the wide array of available CPU architectures (x86-64, Arm, and more) and hardware acceleration options (Intel Movidius VPU, iGPU, FPGA, NVIDIA GPU), plus the dearth of data science professionals to build customized AI, putting together a traditional video analytics solution entails significant time, effort and complexity. The announcements we’re making today further our mission of making video analytics more accessible and useful for everyone—with support for widely used chip architectures, including Intel, NVIDIA and Arm, integration with hardware optimized AI frameworks like NVIDIA DeepStream and Intel OpenVINO, closer integration with complementary technologies across Microsoft’s AI ecosystem—Computer Vision for Spatial Analysis and Cognitive Services Custom Vision, as well as an improved development experience via the Azure IoT Central Custom Vision template and a manufacturing floor reference application. Live video analytics with Computer Vision for Spatial Analysis The Spatial Analysis capability of Computer vision, a part of Azure Cognitive Service, can be used in conjunction with Live Video Analytics on IoT Edge to better understand the spatial relationships between people and movement in physical environments. We’ve added new operations that enable you to count people in a designated zone within the camera’s field of view, to track when a person crosses a designated line or area, or when people violate a distance rule. The Live Video Analytics module will capture live video from real-time streaming protocol (RTSP) cameras and invoke the spatial analysis module for AI processing. These modules can be configured to enable video analysis and the recording of clips locally or to Azure Blob storage. Deploying the Live Video Analytics and the Spatial Analysis modules on edge devices is made easier by Azure IoT Hub. Our recommended edge device is Azure Stack Edge with the NVIDIA T4 Tensor Core GPU. You can learn more about how to analyze live video with Computer Vision for Spatial Analysis in our documentation. Live Video Analytics with Intel’s OpenVINO Model Server You can pair the Live Video Analytics on IoT Edge module with the OpenVINO Model Server(OVMS) – AI Extension from Intel to build complex, highly performant live video analytics solutions. Open vehicle monitoring system (OVMS) is an inference server powered by the OpenVINO toolkit that’s highly optimized for computer vision workloads running on Intel. As an extension, HTTP support and samples have been added to OVMS to facilitate the easy exchange of video frames and inference results between the inference server and the Live Video Analytics module, empowering you to run any object detection, classification or segmentation models supported by OpenVINO toolkit. You can customize the inference server module to use any optimized pre-trained models in the Open Model Zoo repository, and select from a wide variety of acceleration mechanisms supported by Intel hardware without having to change your application, including CPUs (Atom, Core, Xeon), field programmable gate arrays (FPGAs), and vision processing units (VPUs) that best suit your use case. In addition, you can select from a wide variety of use case-specific Intel-based solutions such as Developer Kits or Market Ready Solutions and incorporate easily pluggable Live Video Analytics platform for scale. “We are delighted to unleash the power of AI at the edge by extending OpenVINO Model Server for Azure Live Video Analytics. This extension will simplify the process of developing complex video solutions through a modular analytics platform. Developers are empowered to quickly build their edge to cloud applications once and deploy to Intel’s broad range of compute and AI accelerator platforms through our rich ecosystems.”—Adam Burns, VP, Edge AI Developer Tools, Internet of Things Group, Intel Live Video Analytics with NVIDIA’s DeepStream SDK Live Video Analytics and NVIDIA DeepStream SDK can be used to build hardware-accelerated AI video analytics apps that combine the power of NVIDIA graphic processing units (GPUs) with Azure cloud services, such as Azure Media Services, Azure Storage, Azure IoT, and more. You can build sophisticated real-time apps that can scale across thousands of locations and can manage the video workflows on the edge devices at those locations via the cloud. You can explore some related samples on GitHub. You can use Live Video Analytics to build video workflows that span the edge and cloud, and then combine DeepStream SDK to build pipelines to extract insights from video using the AI of your choice. The diagram above illustrates how you can record video clips that are triggered by AI events to Azure Media Services in the cloud. The samples are a testament to robust design and openness of both platforms. “The powerful combination of NVIDIA DeepStream SDK and Live Video Analytics powered by the NVIDIA computing stack helps accelerate the development and deployment of world-class video analytics. Our partnership with Microsoft will advance adoption of AI-enabled video analytics from edge to cloud across all industries and use cases.”—Deepu Talla, Vice President and General Manager of Edge Computing, NVIDIA Live Video Analytics now runs on Arm You can now run Live Video Analytics on IoT Edge on Linux Arm64v8 devices, enabling you to use low power-consumption, low-footprint devices such as the NVIDIA® Jetson™ series. Develop Solutions Rapidly Using the IoT Central Video Analytics Template The new IoT Central video analytics template simplifies the setup of an Azure IoT Edge device to act as a gateway between cameras and Azure cloud services. It integrates the Azure Live Video analytics video inferencing pipeline and OpenVINO Model Server—an AI Inference server by Intel, enabling customers to build a fully working end-to-end solution in a couple of hours with no code. It’s fully integrated with the Azure Media Services pipeline to capture, record, and play analyzed videos from the cloud. The template installs IoT Edge modules such as an IoT Central Gateway, Live Video Analytics on IoT Edge, Intel OpenVINO Model server, and an ONVIF module on your edge devices. These modules help the IoT Central application configure and manage the devices, ingest live video streams from the cameras, and easily apply AI models such as vehicle or person detection. Simultaneously in the cloud, Azure Media Services and Azure Storage record and stream relevant portions of the live video feed. Refer to our IoT Show episode and related blog post for a full overview and guidance on how to get started. Integration of Cognitive Services Custom Vision models in Live Video Analytics Many organizations already have a large number of cameras deployed to capture video data but are not conducting any meaningful analysis on the streams. With the advent of Live Video Analytics, applying even basic image classification and object detection algorithms to live video feeds can help unlock truly useful insights and make businesses safer, more secure, more efficient, and ultimately more profitable. Potential scenarios include: Detecting if employees in an industrial/manufacturing plant are wearing hard hats to ensure their safety and compliance with local regulations. Counting products or detecting defective products on a conveyer belt. Detecting the presence of unwanted objects (people, vehicles, and more) on-premises and notifying security. Detecting low and out of stock products on retail store shelves or on factory parts shelves. Developing AI models from scratch to perform tasks like these and deploying them at scale to work on live video streams on the edge entails a non-trivial amount of work. Doing it in a scalable and reliable way is even harder and more expensive. The integration of Live Video Analytics on IoT Edge with Cognitive Services Custom Vision makes it possible to implement working solutions for all of these scenarios in a matter of minutes to a few hours. You begin by first building and training a computer vision model by uploading pre-labeled images to the Custom Vision service. This doesn’t require you to have any prior knowledge of data science, machine learning, or AI. Then, you can use Live Video Analytics to deploy the trained custom model as a container on the edge and analyze multiple camera streams in a cost-effective manner. Live Video Analytics powered manufacturing floor reference app We have partnered with the Azure Stack team to evolve the Factory.AI solution, a turn-key application that makes it easy to train and deploy vision models without the need for data science knowledge. The solution includes capabilities for object counting, employee safety, defect detection, machine misalignment, tool detection, and part confirmation. All these scenarios are powered by the integration of Live Video Analytics running on Azure Stack Edge devices. In addition, the Factory.AI solution also allows customers to train and deploy their own custom ONNX models using Custom Vision SDK. Once a custom model is deployed on the edge, the reference app leverages gRPC from Live Video Analytics for high frame rate accurate inferencing. You can learn more about the manufacturing reference app at Microsoft Ignite or by visiting the Azure intelligent edge patterns page. Get started today In closing, we’d like to thank everyone who is already participating in the Live Video Analytics on IoT Edge preview. We appreciate your ongoing feedback to our engineering team as we work together to fuel your success with video analytics both in the cloud and on the edge. For those of you who are new to our technology, we’d encourage you to get started today with these helpful resources: Watch the Live Video Analytics introduction video. Find more information on the product details page. Watch the Live Video Analytics demo. Try the new Live Video Analytics features today with an Azure free trial account. Register on the Media Services Tech Community and hear directly from the Engineering team on upcoming new features, to provide feedback and discuss roadmap requests. Download Live Video Analytics on IoT Edge from the Azure Marketplace. Get started quickly with our C# and Python code samples. Review our product documentation. Search the GitHub repo for Live Video Analytics open source projects. Contact amshelp@microsoft.com for questions. Intel, the Intel logo, Atom, Core, Xeon, and OpenVINO are registered trademarks of Intel Corporation or its subsidiaries. NVIDIA and the NVIDIA logo are registered trademarks or trademarks of NVIDIA Corporation in the U.S. and/or other countries. Other company and product names may be trademarks of the respective companies with which they are associated. View the full article

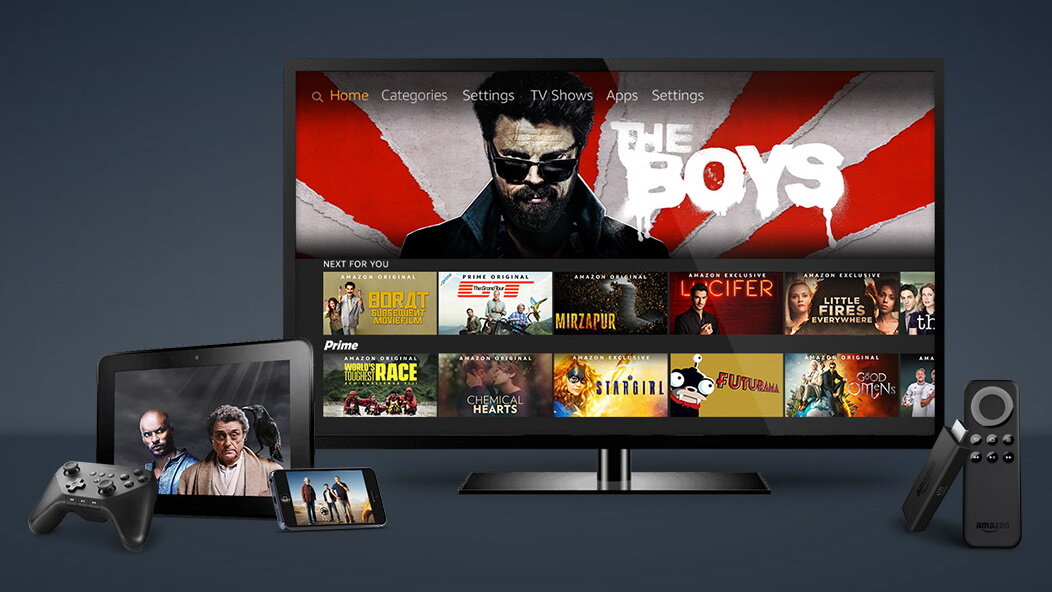

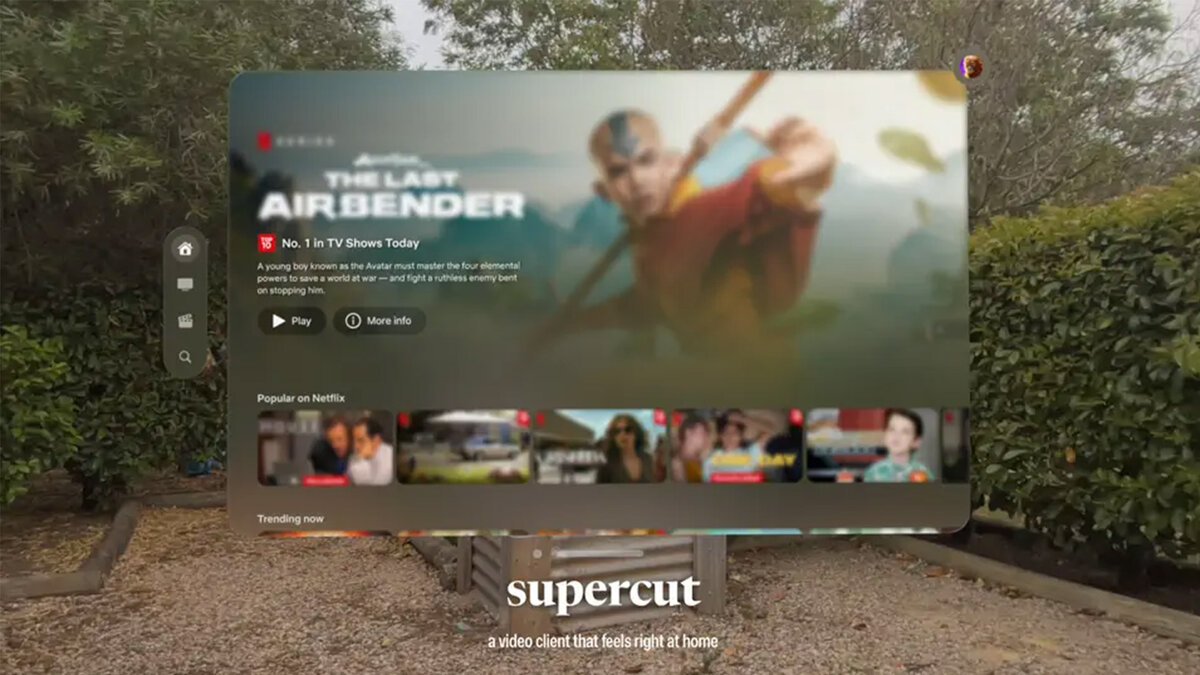


-
Forum Statistics
43.2k
Total Topics42.5k
Total Posts